
 tcp缓存引起的日志丢失
tcp缓存引起的日志丢失
# 背景
logstash从数据源拉取日志,然后通过tcp插件发送到proxy进程中。在业务侧发现日志量明显少了,所以有了这一次的问题排查。
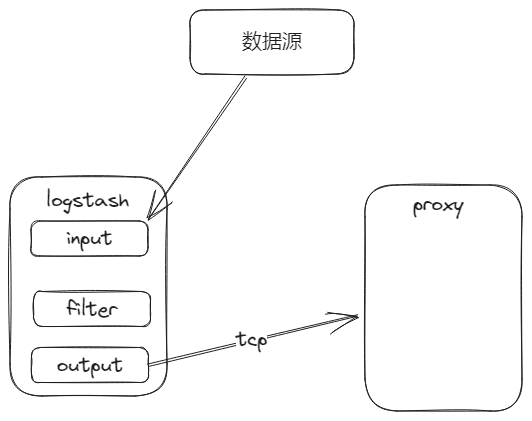
# 问题排查定位
首先从logstash侧开始检查。我们先看logstash的日志,没有明显的报错信息。
然后再查看logstash管道的状态。可以很明显的看到,在output管道中,in远远大于out,也就是logstash拉取的日志已经到了output管道,但是无法输出出去,并且duration_in_millis时间很长,这个代表着发出去的速率很慢,这是什么原因呢?
curl -XGET 'localhost:9600/_node/stats/pipelines/azure_event_hubs?pretty'
{
...
"outputs" : [ {
"id" : "99b12e190d297be5d6113d04cf10089a3dccbaef7eed0cc41515e8e5af5f4595",
"name" : "tcp",
"events" : {
"in" : 341,
"out" : 69,
"duration_in_millis" : 519709
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
要么是发送方的原因,要么是接收方的原因。我先从发送方进行排查,我在output管道中,除了tcp插件外,还添加了stdout插件,也就是日志来了除了会通过tcp发送外,还会打印在标准输出中。
output {
tcp {
...
}
stdout {}
}
2
3
4
5
6
7
8
9
10
然后等待一段时间,然后再查看该管道的信息,stdout插件的in和out完全相等,但tcp插件in和out还是相差甚大,也就是output管道应该没问题。
我再假设proxy端有问题。日志是可以从logstash端发送到proxy端的,只是很慢,并且还有其他数据源也在往proxy端发送日志,也没有这个问题,所以我突然想到,该数据源的日志很大,会不会是这个原因导致的呢?
我从上面标准输出中抓了一条日志出来,134k大小,然后我手动的用nc命令将日志发送到proxy,因为日志很大,我是将日志写入到文件,然后再用管道的方式发送的
cat test.txt | nc
通过查看proxy的日志发现,其根本没有收到该条日志。那么问题原因找到了,就是因为日志太大,导致日志发生了丢失。
# 代码排查
proxy服务的是golang写的,通过查看代码,这里使用了bufio.NewScanner来循环读取连接中的数据。
scanner := bufio.NewScanner(conn)
for scanner.Scan() {
// 处理数据
msg := scanner.Text()
...
2
3
4
5
6
查看NewScanner方法可以看到有一个maxTokenSize参数,然后用的默认值MaxScanTokenSize
func NewScanner(r io.Reader) *Scanner {
return &Scanner{
r: r,
split: ScanLines,
maxTokenSize: MaxScanTokenSize,
}
}
2
3
4
5
6
7
再跳转,有一个初始化缓存大小startBufSize为4k和最大的缓存大小MaxScanTokenSize为64k。但是我们的日志大小为134k,已经大于最大大小了,所以无法接收到该日志,也就是因为这个原因导致了日志发生了丢失。
const (
MaxScanTokenSize = 64 * 1024
startBufSize = 4096
)
2
3
4
5
我们再看下Scan方法,有一段代码如下,如果拿到的数据的大小大于maxTokenSize,则会使用s.setErr(ErrTooLong)记录错误,然后返回false
func (s *Scanner) Scan() bool {
..
const maxInt = int(^uint(0) >> 1)
if len(s.buf) >= s.maxTokenSize || len(s.buf) > maxInt/2 {
s.setErr(ErrTooLong)
return false
}
newSize := len(s.buf) * 2
if newSize == 0 {
newSize = startBufSize
}
if newSize > s.maxTokenSize {
newSize = s.maxTokenSize
}
newBuf := make([]byte, newSize)
copy(newBuf, s.buf[s.start:s.end])
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
但是我们在业务代码中,并没有判断该错误,也就是如果Scan方法虽然返回了false,循环结束了,但是并没有任何错误信息。也就是无法发现该问题。
# 解决方法
将TCP的最大缓存大小修改为配置文件可配置的,这样如果日志很大,可以修改配置增大缓存上限。库中有提供
Buffer方法来设置该上限。在Scan发生错误时,打印错误日志,代码如下:
scanner := bufio.NewScanner(conn)
for scanner.Scan() {
// 处理数据
msg := scanner.Text()
...
if err := scanner.Err(); err != nil {
log.Errorf("扫描输入时发生错误:%s", err)
}
2
3
4
5
6
7
8
9
10
11
# 总结
- 要提高自己的排查的手段,熟悉组件提供的排查机制,让你事半功倍。
- 每一个提供的参数都至关重要,所以我们都需要有一定的理解,可以减少BUG的发生