
 docker容器
docker容器
# docker容器
# 容器是什么?
容器,就是一个被隔离的进程。
# 为什么要隔离?
- 将应用程序与外界系统隔离,保证容器外系统安全
- 资源隔离,只能使用指定配额
# 和虚拟机的区别是什么?
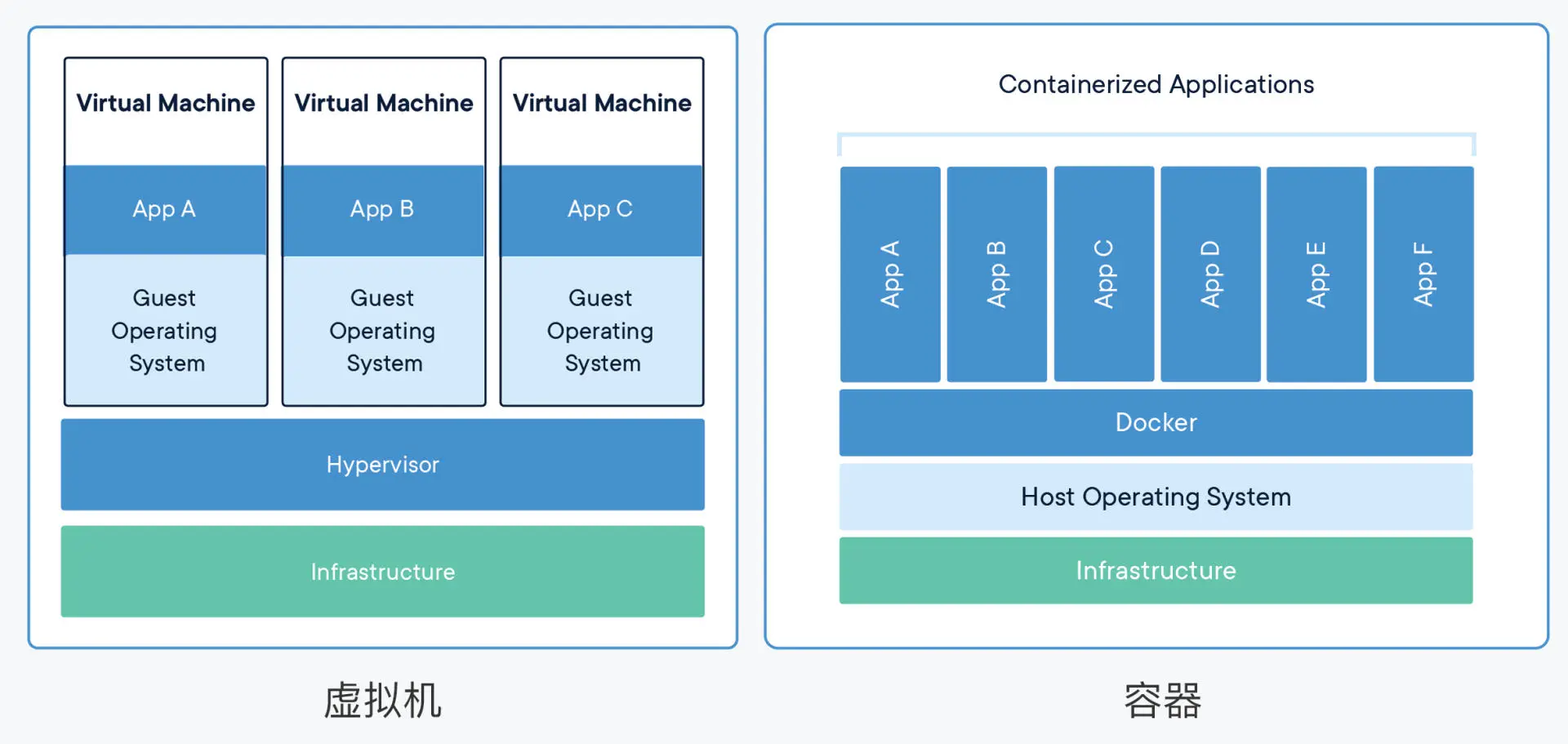
虚拟机:虚拟的是硬件,需要在上面安装操作系统才能运行应用程序。
容器:共享下层的硬件和操作系统。
下图是官方的图 (opens new window)
其实上图关于容器的部分并不准确,APP也就是容器并不是运行在Docker上的,Docker只是在帮助用户创建进程时添加了各种Namespace参数,容器是特殊的进程,还是运行在操作系统上的。
| 实现方式 | 优势 | 劣势 | |
|---|---|---|---|
| 虚拟机 | 虚拟化硬件 | 隔离程度非常高 | 资源消耗大,启动慢 |
| 容器 | 直接利用下层的硬件和操作系统 | 资源利用率高,运行速度快 | 隔离程度低, 安全性低 |
虚拟机是硬件级别的隔离,而容器化是进程间的隔离。
虚拟化需要模拟硬件占用部分内存,并且对宿主机操作的系统调用需要经过虚拟化软件的拦截与转换,造成资源的开销。而容器就是一个普通的进程,基本无额外的计算资源的开销。
在Linux内核中有部分的资源和对象无法namespace化,如时间。
因为容器是共享宿主机内核,所以对外暴露的供给面非常的大。
# 什么是容器化应用?
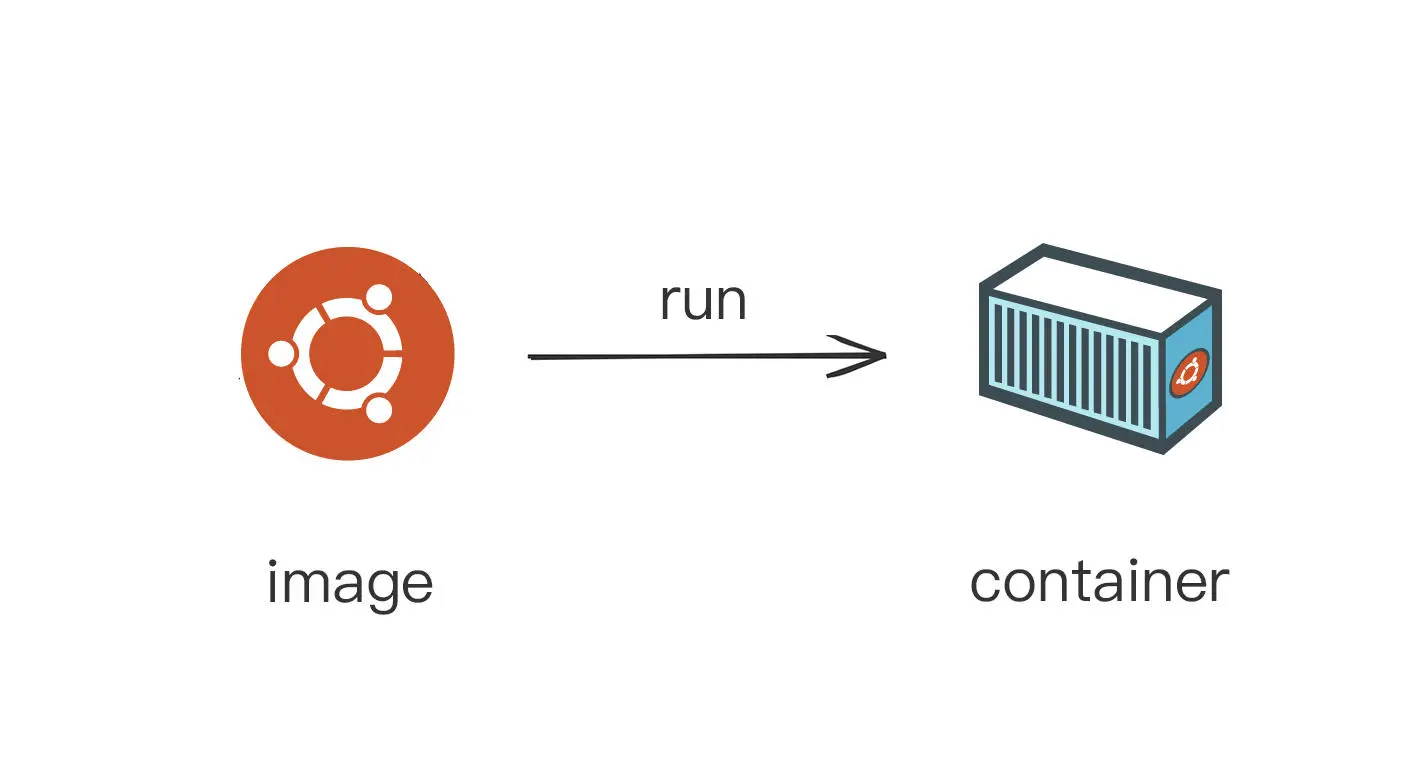
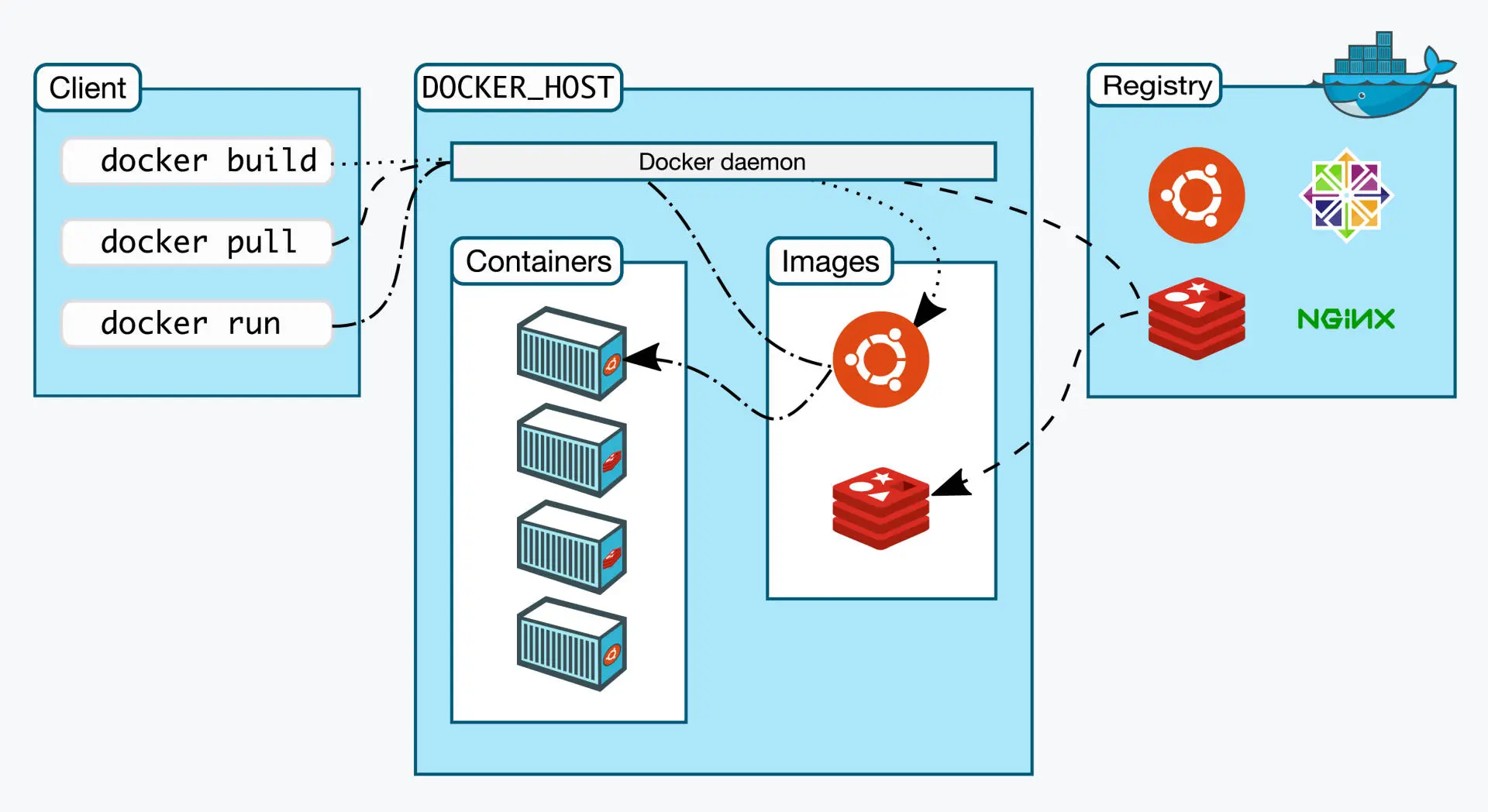
镜像,就是将容器的初始化环境固化下来,将运行进程所需要的文件系统、依赖库、环境变量、启动参数等打包整合到一起,保存成一个静态的文件。
容器化环境可以通过镜像快速重建容器,应用程序看到的就是一致的运行环境。
容器化应用,也就是应用程序不直接与操作系统去打交道,而是将应用程序打包成镜像,再交给容器环境去运行
镜像与容器的关系还可以用"序列化"和"反序列化"来理解,镜像就是序列化到磁盘的数据,而容器是反序列化后内存中的对象。
# docker架构
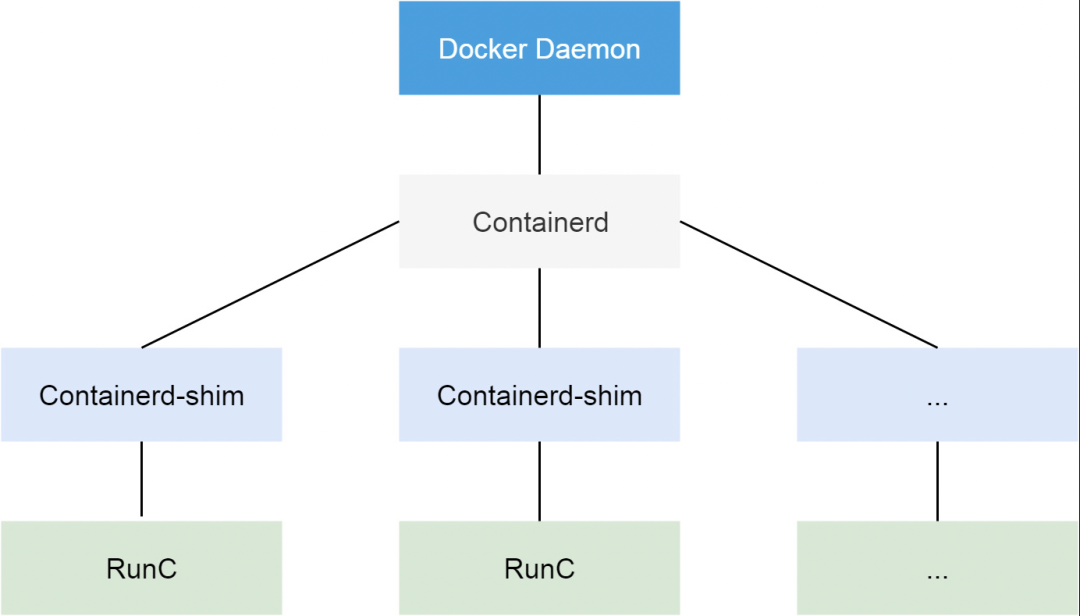
创建容器时,我们通过docker命令请求Docker Daemon服务,然后该服务再通过RPC请求Containerd进程,该进程会创建Containerd-shim进程,该进程会再创建RunC进程,该进程是真正创建容器的是进程,等容器创建好后,RunC会退出,容器的父进程会变成Containerd-shim,当容器结束时,Conatinerd-shim会回收容器进程的资源,以防止僵尸进程。
# 常用镜像操作
| 命令 | 作用 |
|---|---|
| docker pull | 从远端仓库拉取镜像 |
| docker images | 列出当前本地已有镜像 |
| docker rmi | 删除不再使用的镜像 |
# 常用容器操作
| 命令 | 作用 | 例子 |
|---|---|---|
| docker run | 使用镜像启动容器 | |
| docker ps | 列出正在运行的容器 | |
| docker exec | 在容器内执行另一个程序 | |
| docker stop | 停止容器 | |
| docker start | 将停止的容器再次启动 | |
| docker rm | 删除容器 | |
| docker export | 将容器内的文件系统导出 | docker export -o rootfs.tar 容器ID |
容器被停止后,docker ps命令就看不到该容器了,需要使用docker ps -a来查看所有容器,包括已经停止的容器。
可能会导致非常多已经停止的容器占用系统资源,所以建议docker run时添加--rm参数,在容器运行完毕时自动清除
docker exec是如何进入到容器中的?
该命令会创建一个新的进程加入到容器的namepsace中。
/proc/{进程ID}/ns/下的虚拟文件会链接到真实的Namespace文件上。通过查看exec创建的进程ns文件可以看出和容器的Namespace文件一致
[root@k8s-master proc]# ll /proc/288948/ns/pid
lrwxrwxrwx 1 root root 0 Jul 8 11:27 /proc/288948/ns/pid -> 'pid:[4026532247]'
[root@k8s-master proc]# ll /proc/289220/ns/pid
lrwxrwxrwx 1 root root 0 Jul 8 11:27 /proc/289220/ns/pid -> 'pid:[4026532247]'
2
3
4
5
docker run和docker exec的区别是什么?
run是将镜像运行成容器并执行命令,该命令为1号进程。
exec是在容器中执行一个命令,该命令是另一个进程,加入到了容器的namespace中。
# 容器镜像
# 镜像内部机制
容器镜像内部是由许多的镜像层(Layer)组成的,每层都是只读不可修改的一组文件,相同的层可以在镜像中共享,然后多个层像搭积木叠加起来,使用**联合文件系统(UnionFS)**将它们合并起来,最终形成容器看到的文件系统。
镜像中的层级是只读层,而容器所在的层级是可读写层。
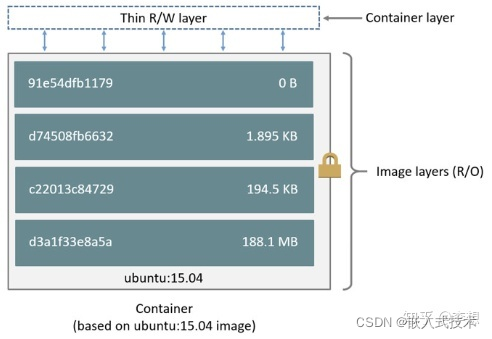
镜像的分层信息可以通过命令docker inspect 镜像名称获取,其中RootFs是对应的信息
>>> docker inspect b3log/siyuan
.....
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:24302eb7d9085da80f016e7e4ae55417e412fb7e0a8021e95e3b60c67cde557d",
"sha256:e7356c89d8c31fc628769b331f73d6e036e1d5900d2d2a3990c89ef91bce707a",
"sha256:90358380b9ea63cfb8832ae627455faf85596e822ff8abe9e1d7c8bbd93804ad",
"sha256:c6d8ffacc07d179562cd70114402e549d9fce92b12a019d3f4003eb94944d089"
]
}
....
2
3
4
5
6
7
8
9
10
11
12
13
好处是,如果多个镜像使用了相同的层,可以直接共享,减少磁盘空间的占用。比如nginx镜像和Tomcat镜像都是用了基础镜像centos,那么该基础镜像可以共享。
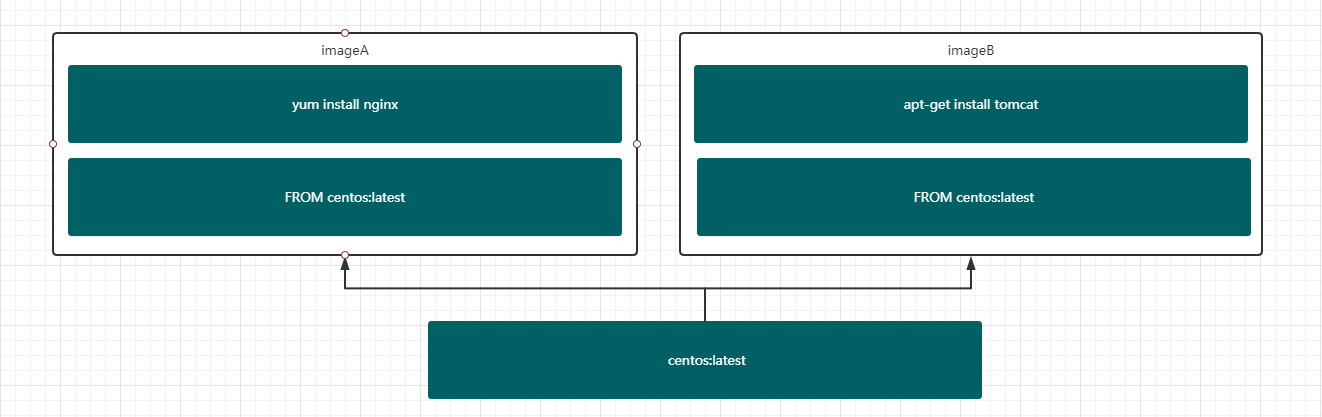
OverlayFS
镜像层和容器是如何合并的呢?
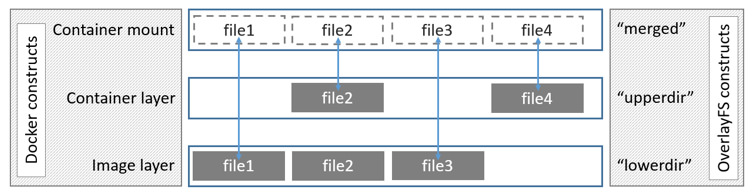
lowerdir是镜像层,upperdir是容器层,如果双方有相同文件则展示容器层的文件。
在容器写文件时,会先从镜像层拷贝一份文件到容器层,然后再写入,使用的是**写时复制(copy on write)**策略
例子
overlay2
├── lowerdirA
│ ├── a 内容:AA
│ └── b 内容:AA
├── lowerdirB
│ └── a 内容: BB
├── merge
├── upper
└── work
2
3
4
5
6
7
8
9
执行以下命令使用overlay进行合并层
mount -t overlay overlay -o lowerdir=lowerdirA:lowerdirB,upperdir=upper,workdir=work merge
lowerdir为镜像层,upperdir为容器层,merge目录为最终展示层。
可以看到merge目录中的a文件内容lowerdirA镜像层的内容
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# cat merge/a
AA
2
当我们修改megre目录中的a文件时,可以看到upperdir目录的会生成a文件并且内容修改后的内容
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# ls upper/
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# echo upper > merge/a
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# ls upper/
a
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# cat upper/a
upper
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# cat merge/a
upper
2
3
4
5
6
7
8
当删除文件merge/a时,会出现什么情况呢?
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# rm merge/a
rm: remove regular file ‘merge/a’? y
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# ll lowerdirA/
total 8
-rw-r--r-- 1 root root 3 Jul 12 19:11 a
-rw-r--r-- 1 root root 3 Jul 12 19:10 b
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]# ll upper/
total 0
c--------- 1 root root 0, 0 Jul 12 19:31 a
[root@iZwz93q4afq8ck02cesqh4Z k8s_learn]#
2
3
4
5
6
7
8
9
10
可以看出镜像层lowerdirA的文件a是不变的,而在容器层upper中的a文件类型变成了c,该文件类型,最终在展示层看不到该文件了。
可以使用命令docker inspect来查看layer的路径
>>> docker inspect xxx
....
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/641e486c54d15d2a8d807fd8964f4a4b8687cbcf95c176cd9a46553b1e80341d/diff:/var/lib/docker/overlay2/ed9ad4fb9d0f9bf3aea553c634e54fef89448cf43c5b662468d79f01cf41d0c3/diff:/var/lib/docker/overlay2/9db169e1ad2165f688e652ef06dfe9a3e465c31299f3c357a37a6919747efbc8/diff",
"MergedDir": "/var/lib/docker/overlay2/fa3166e545a2d1811dbeecb6f1fdda96b9f97b3cd629f32a8ea378aa79b1c780/merged",
"UpperDir": "/var/lib/docker/overlay2/fa3166e545a2d1811dbeecb6f1fdda96b9f97b3cd629f32a8ea378aa79b1c780/diff",
"WorkDir": "/var/lib/docker/overlay2/fa3166e545a2d1811dbeecb6f1fdda96b9f97b3cd629f32a8ea378aa79b1c780/work"
},
"Name": "overlay2"
},
....
2
3
4
5
6
7
8
9
10
11
12
13
14
# Dockerfile
Dockerfile是一个用来创建镜像的文本文件,该文件中的每一条命令都会成生成一个layer。
例子:
最简单的Dockerfile的例子
FROM busybox # 选择基础镜像
CMD echo "hello world" # 启动容器时默认运行的命令
2
FROM指令是构建使用的基础镜像
CMD指令是用于启动容器时默认运行的命令
使用docker build 即可执行创建镜像
docker build -f Dockerfile .
Sending build context to Docker daemon 7.68kB
Step 1/2 : FROM busybox
---> d38589532d97
Step 2/2 : CMD echo "hello world"
---> Running in c5a762edd1c8
Removing intermediate container c5a762edd1c8
---> b61882f42db7
Successfully built b61882f42db7
2
3
4
5
6
7
8
9
10
# 容器与外部的交互
如何拷贝宿主机的文件到容器内
可以使用docker cp命令将宿主机的文件拷贝到容器中。
docker cp a.txt 062:/tmp
其中的062为容器ID,如果想将容器中的文件拷贝到宿主机中,反过来即可。
docker cp 062:/tmp/a.txt /tmp
注意,这里的拷贝是临时的,拷贝进容器中的文件只存在于容器中,不存在与镜像中,如果想要将文件拷贝到镜像中,在写Dockerfile时使用copy命令拷贝即可。
宿主机与容器共享文件夹
在使用镜像运行容器时,使用参数-v可以将宿主机中的文件夹映射到容器中,双方修改该文件夹中的内容,都可以及时看到。
docker run -d --rm -v /tmp:/tmp redis
如何实现网络互通?
docker提供三种网络模式:
- null,无网络
- host,直接使用宿主机网络,在创建容器时,使用--net=host参数。
其实就是创建新的namespace,而是直接加入到宿主机的namesapce
docker run -d --rm --net=host nginx:alpine
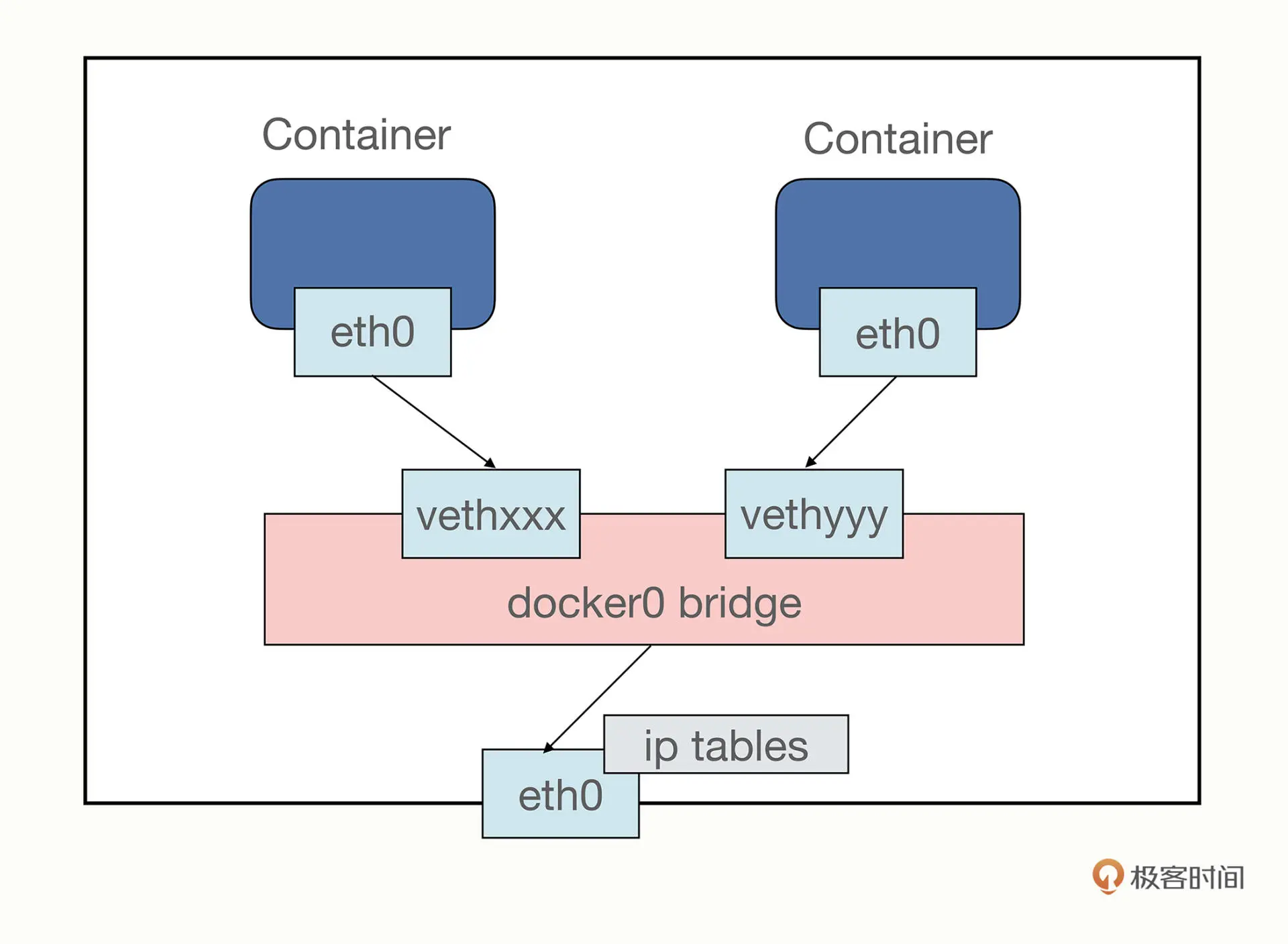
- bridge,桥接模式,由软件虚拟网卡与网桥,容器和宿主机都接入该网桥,即可正常发送数据包。可以使用参数
--net=bridge创建容器,但这个是默认参数。
docker run -d --rm nginx:alpine
| 网络模式 | 优点 | 缺点 |
|---|---|---|
| host | 因为是直接使用宿主机的网络,效率更高 | 运行太多的容器,会导致端口发生冲突 |
| bridge | 因为有了网桥可以设置更多的策略,比如流量控制等 | 需要软件模拟虚拟网卡与网桥,效率更低 |
# 关于k8s与docker的关系
在2014年的时候,Docker如日中天,那么k8s自然选择基于docker上运行。
在2016年k8s加入了CNCF,一个开源的云原生计算基金会。
并且引入了一个接口标准:CRI,Container Runtime Interface。也就是规定kubelet该如何调用Container Runtime去管理容器和镜像,但这是一套全新的接口,和之前的Docker完全不兼容。目的很明显,不想绑定Docker,可以随时将Docker踢掉。
因为docker已经非常成熟,各大厂商不可能将Docker全部替换。所以k8s在kubelet和Docker中间加一个"适配器",把Docker的接口转换成符合CRI标准的接口。
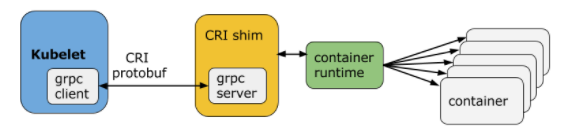
什么是containerd?
不过 Docker 也没有“坐以待毙”,而是采取了“断臂求生”的策略,推动自身的重构,把原本单体架构的 Docker Engine 拆分成了多个模块,其中的 Docker daemon 部分就捐献给了 CNCF,形成了 containerd。
containerd 作为 CNCF 的托管项目,自然是要符合 CRI 标准的。但 Docker 出于自己诸多原因的考虑,它只是在 Docker Engine 里调用了 containerd,外部的接口仍然保持不变,也就是说还不与 CRI 兼容。
由于 Docker 的“固执己见”,这时 Kubernetes 里就出现了两种调用链:第一种是用 CRI 接口调用 dockershim,然后 dockershim 调用 Docker,Docker 再走 containerd 去操作容器。第二种是用 CRI 接口直接调用 containerd 去操作容器。
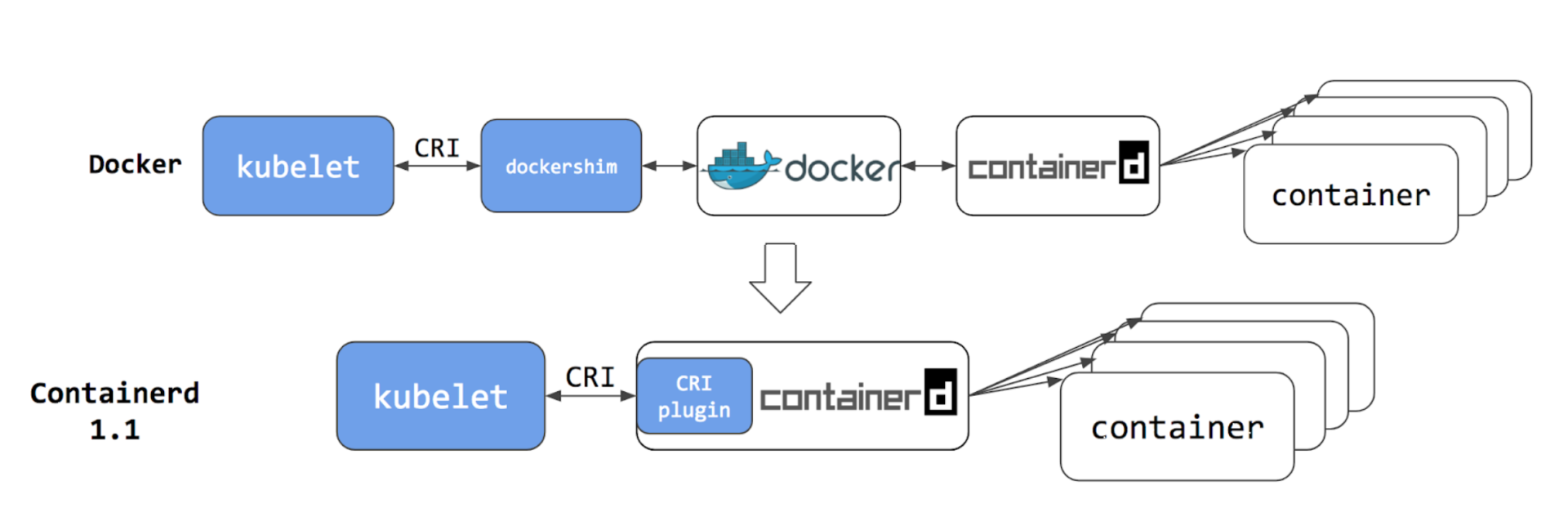
显而易见,使用第二种省去了dockershim和Docker Engine两个环节,损耗更少,性能也提升了。
正式"弃用Docker"
在2020年K8s弃用Docker支持,但该弃用支持弃用了"dockershim"的这个组件,也就是把dockershim移出kubelete,只是绕过Docker,直接调用了Docker内部的containerd而已。
并且对docker也无影响,因为docker内部也是使用开源的containerd。
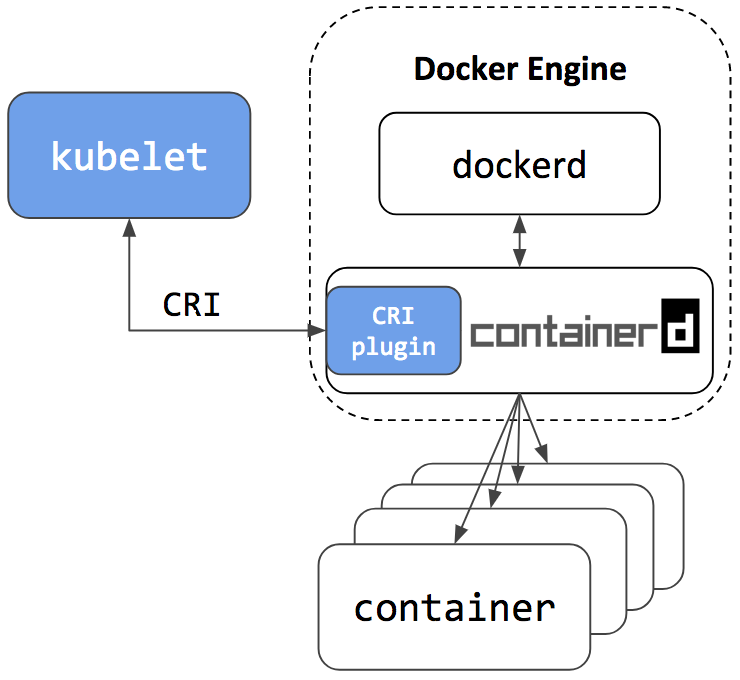
唯一影响的是,k8s是直接操作containerd操作容器,那么它和docker是独立的工作环境,彼此都不能访问对方的容器和镜像,也就是docker ps看不到k8s运行的容器。改用crictl命令。
Docker 重构自身,分离出 containerd,这是否算是一种“自掘坟墓”的行为呢?如果没有 containerd,那现在的情形会是怎么样的呢?
Docker 是一个完整的软件产品线,不止是 containerd,它还包括了镜像构建、分发、测试等许多服务,甚至在 Docker Desktop 里还内置了 Kubernetes。
docker分离containerd是一个很聪明的举动!与其将来被人分离或者抛弃不用,不如我主动革新,把Kubernates绑在我的战车上,这样cri的第一选择仍然是docker的自己人。
一时的退让是为了更好的将来。