
 redis之持久化
redis之持久化
# 0. 前言
本文主要是介绍 redis 是如何进行持久化数据的,我们知道 redis 是基于内存的数据库,那么只要服务器一旦宕机,那么数据则将全部丢失,如果从后端数据库进行恢复,则可能导致性能变慢,那么 redis 需要自身持久化,而不通过后端数据库来恢复数据是重要的。
# 1. AOF
AOF,称为后写日志,就是先执行命令,把数据写入到数据库中之后,再进行记录日志。过程如下图所示:
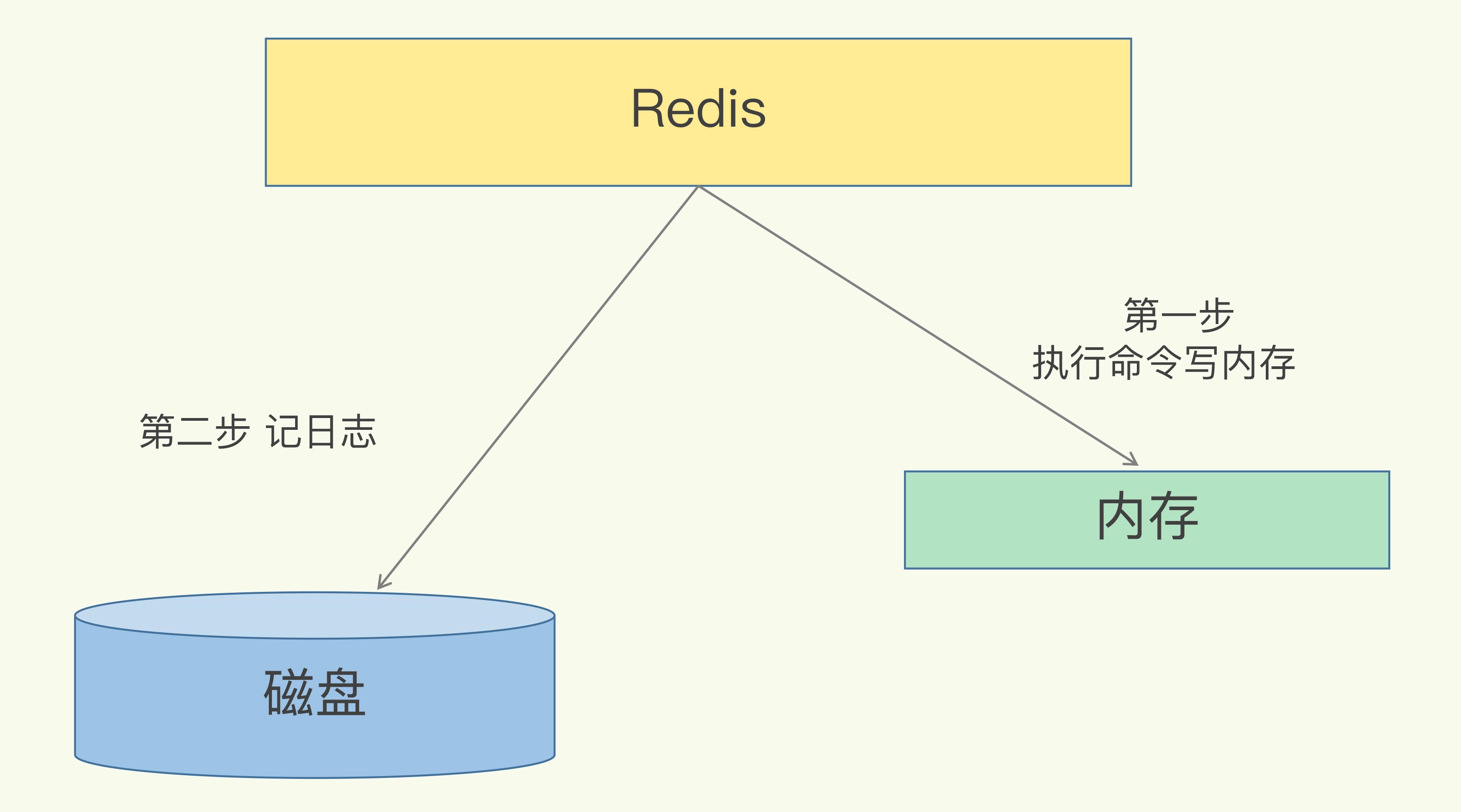
# 1.1 为什么是 AOF ?
Redis 向 AOF 写日志时,并不会校验命令的语法,如果先记日志,则可能保存了错误的命令导致出错。所以让系统先执行命令,执行成功后再记录日志。
后写日志也不会阻塞当前操作,但是下一次操作有阻塞风险。AOF 也是在主线程执行,如果写入的时候磁盘压力过大,就可能会大致阻塞。
但该种方式有风险,如果写入内存成功,记日志时发生宕机,则会丢失日志。
正因为有这个风险,所以 redis 提供三种写入策略:
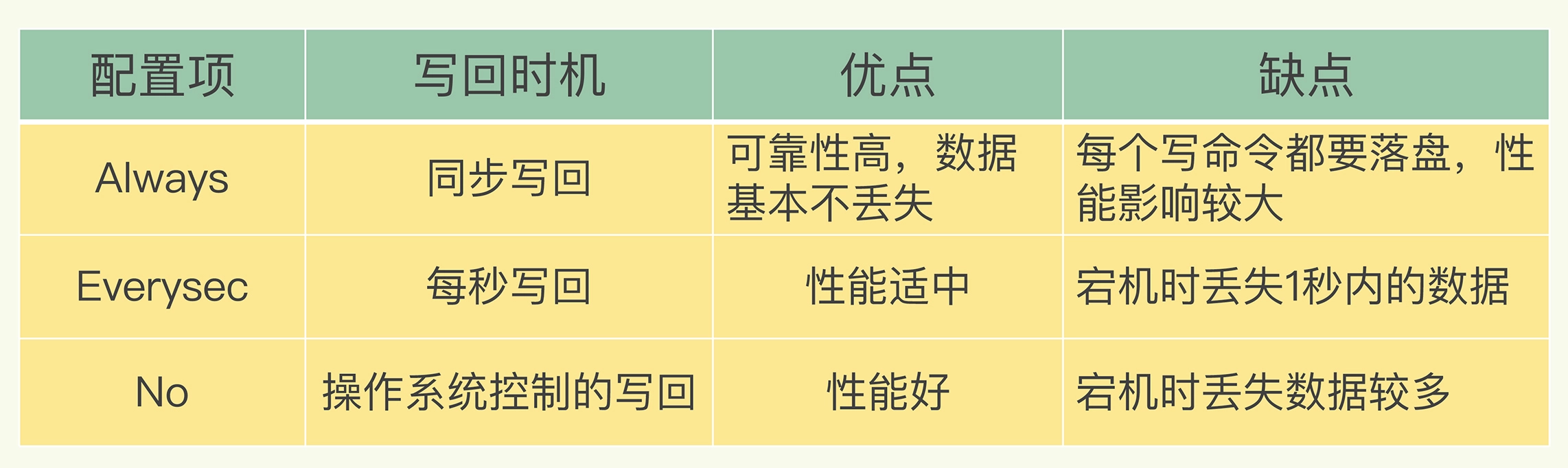
这三种策略就是性能与可靠性的权衡,可以根据具体的业务进行选择。
# 1.2 AOF 重写机制
AOF 记录的是 Redis 的每一条命令,以文本形式保存,那么当 AOF 日志写的越来越多的时候,AOF 文件越来越大,以后通过 AOF 恢复数据也会变得很慢,redis 提供了 AOF 重写机制来减小 AOF 日志文件。
将 AOF 文件生成的最新数据生成最新的操作日志并记录到新的 AOF 文件中,这样新的 AOF 文件中就没有了冗余命令,再替换掉旧的 AOF 文件。
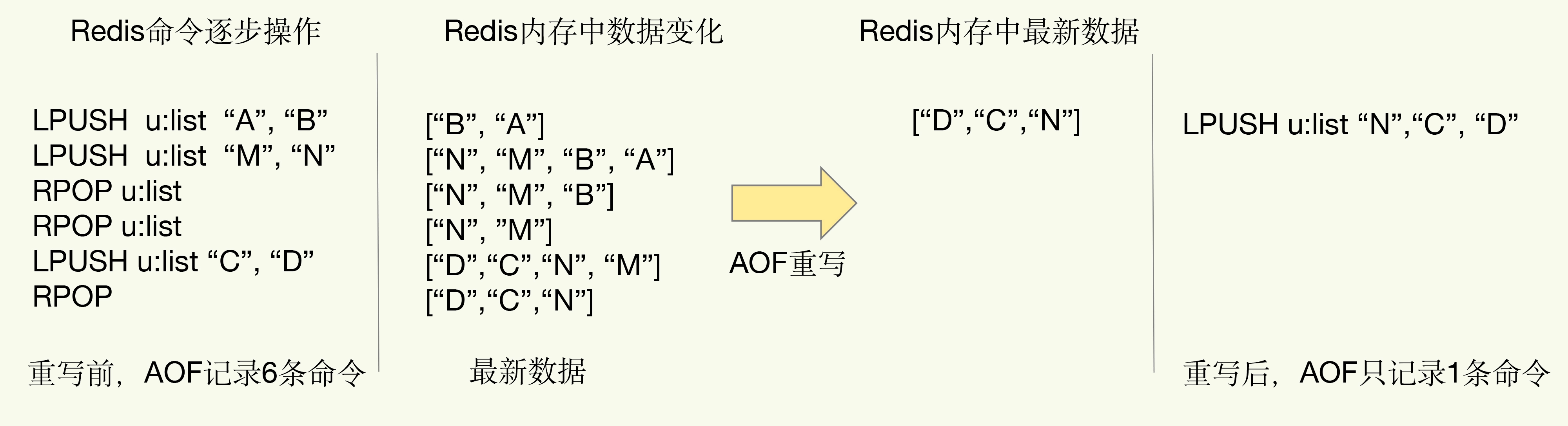
AOF 重写过程
AOF 重写的过程会 fork 出 bgrewriteof 后台子进程,fork 会将主线程的数据内存拷贝到子进程,子进程在不影响主线程的情况下将拷贝的数据转换成操作写入到重写日志中。
在重写日志时,主线程任然接受新的操作,操作会记录到 AOF 缓冲和 AOF 重写缓冲区,AOF 日志不会丢失最新的操作,在拷贝数据重写完成后,再将 AOF 重写缓冲区的日志记录写入新的 AOF 文件中,保证新的 AOF 文件的数据也是最新的状态。此时就可以放心将新写入的 AOF 文件代替旧文件。
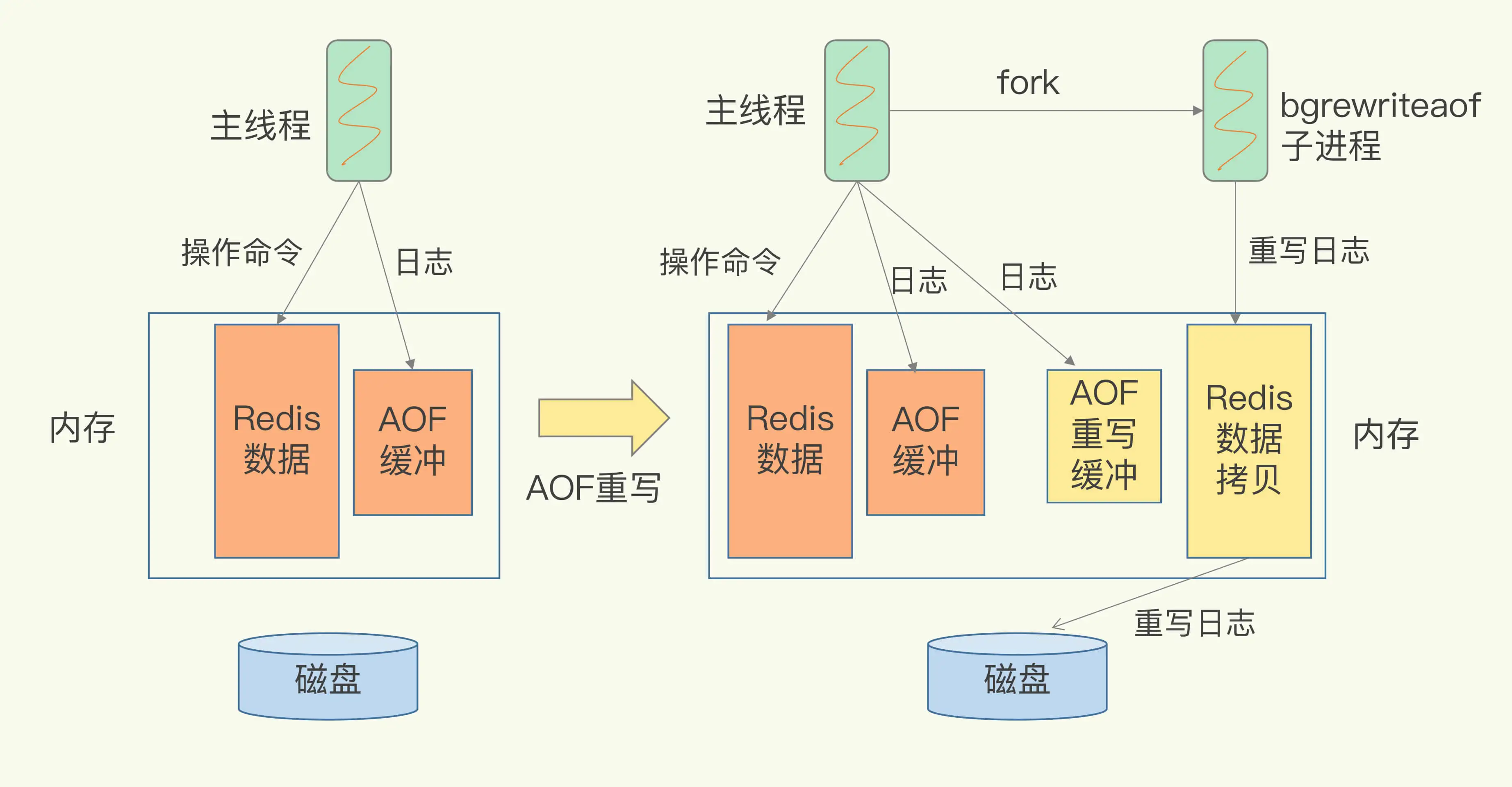
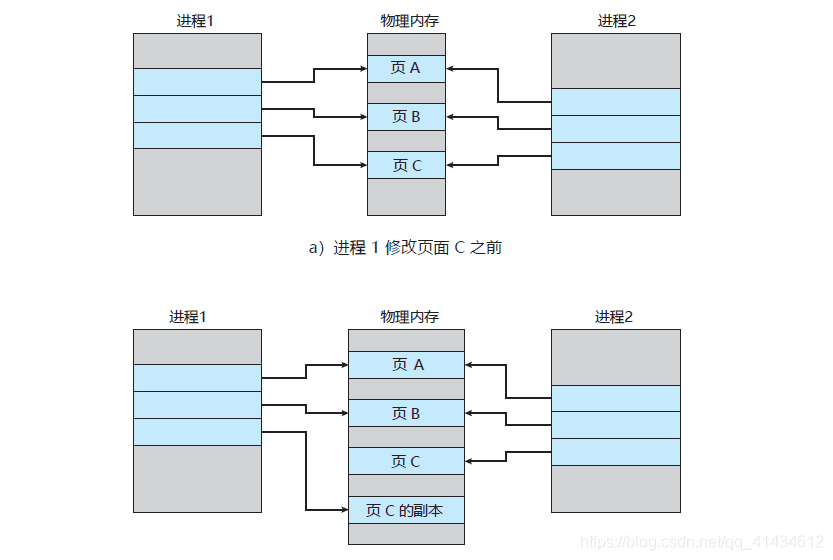
写时复制 copy on write
fork 采用操作系统的 写时复制机制,避免一次性拷贝大量内存数据给子进程。fork 子进程时,子进程会拷贝父进程的内存页表(虚拟内存和物理内存的映射索引表)而不会拷贝其所有的物理内存数据,这样两个进程使用的数据是同一份内存空间。当主线程写入新数据时,会拷贝一份新数据并进行修改,这样并不影响子进程的读取。
AOF 重写阻塞点
- 在 fork 子进程时,即使是拷贝页表和一些必要的数据结构也是需要消耗大量的 CPU,会对主线程进行阻塞
- 在 AOF 重写过程中,如果有 big key 写入时,会拷贝旧数据到创建的新内存空间中,也会进行阻塞。
AOF 重写日志为什么不共享 AOF 本身日志?
- 两个进程操作同一个文件,存在竞争问题,影响父进程性能
- 如果重写失败,AOF 日志则被污染了,无法恢复使用。重写一个文件,如果重写失败,删除重来即可。
# 2. RDB 内存快照
AOF 方法恢复数据需要将操作日志全部执行一遍,如果日志非常多,则恢复的过程缓慢。而内存快照是将某一时刻的数据以文件(RDB)记录到磁盘上,在恢复的时候,直接读入内存即可。
会不会阻塞主线程?
Redis 提供 save 和 bgsave 两个命令生成 RDB 文件
- save 是在主线程执行会阻塞,不建议在线上使用
- bgsave 会创建子进程生成 RDB,默认。
如果在触发快照时,能修改数据吗?
如果在 t 时刻,需要快照数据 A,在快照时修改了 A 数据为 A',这时破坏了快照的完整性,这时 A'并不是 t 时刻的状态。
如果在快照时,不允许修改,虽然解决了上面的问题,但是会影响业务。
这里解决办法还是使用了操作系统的 写时复制机制,在新的数据需要写入时,主线程会将该数据复制一份,然后对该副本进行修改,而子进程使用原来的数据进行快照。
既然可以使用 RDB 快速恢复数据,那么是否可以每秒做一次快照呢?
两次快照之间的数据,如果遇到宕机,可能会发生丢失,所以需要尽量短的时间做快照。
但虽然生成 RDB 文件使用子进程,但是频繁的执行全量快照还是会带来额外的开销:
- 频繁的写磁盘,增大磁盘压力
- fork 子进程时,如果数据内存过大,是会阻塞主线程的。
如何解决快照间丢失数据?
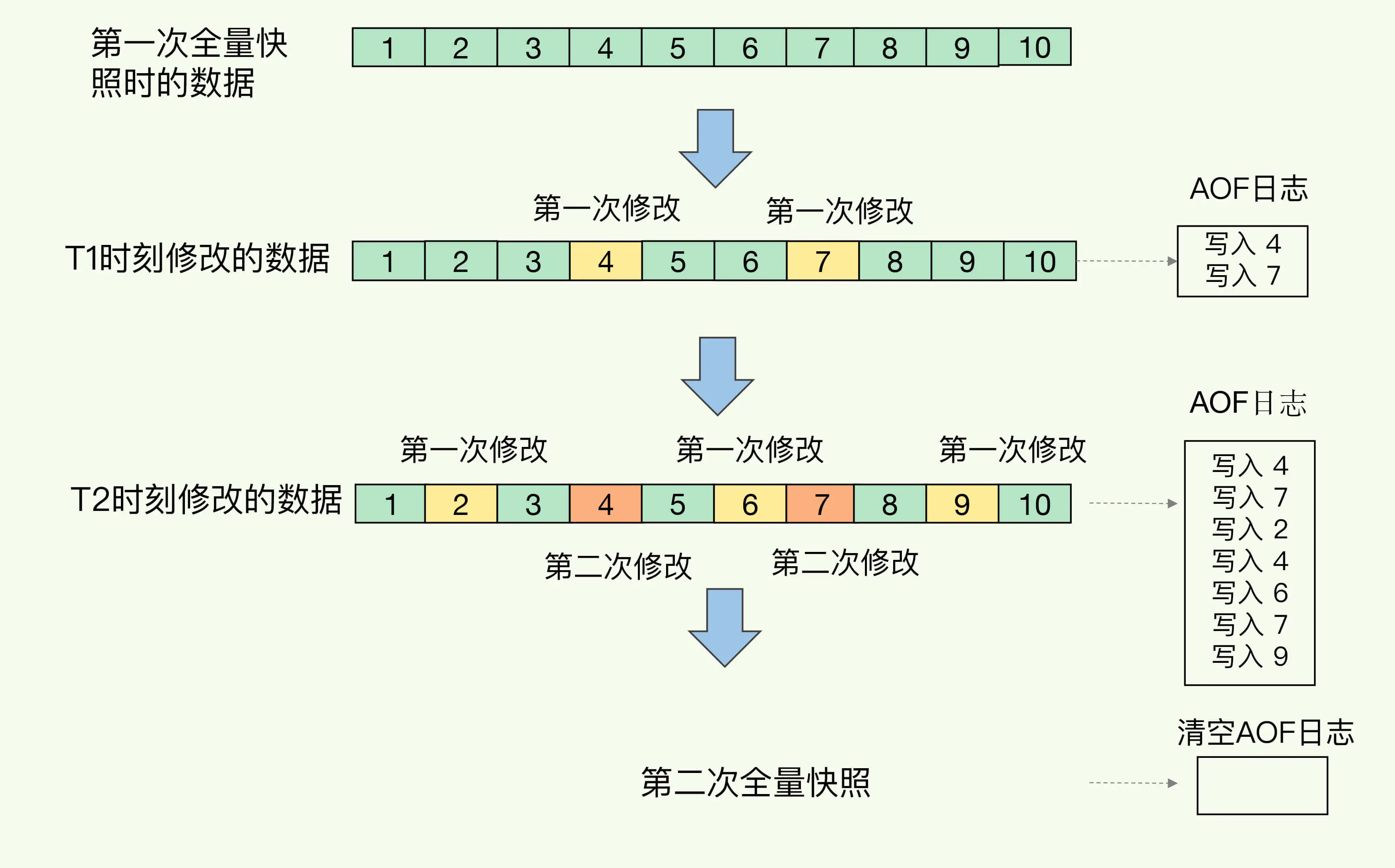
增量快照。混合使用 AOF 日志和内存快照。
使用 AOF 记录两次快照间的操作。在生成快照时,使用 AOF 日志记录新进入的修改操作,在下一次快照前宕机都可以通过 AOF 日志进行恢复。下一次快照时可以再清空 AOF 日志重新记录
如何在 AOF 和 RDB 进行选择?
- 数据不能丢失时,内存快照和 AOF 的混合使用是一个很好的选择;
- 如果允许分钟级别的数据丢失,可以只使用 RDB;
- 如果只用 AOF,优先使用 everysec 的配置选项,因为它在可靠性和性能之间取了一个平衡。
# 3. 总结
通过上面的介绍,了解到 RDB 和 AOF 都是通过 fork 子进程来完成的,是为了不会造成主线程的阻塞,但是也并不能完全避免,所以我们需要尽可能的降低 fork 的频率。
并且都使用了操作系统的 COW 机制,该机制可以大大的减少 cpu 与内存的消耗,我们在很多组件中会发现它们都用到了 linux 的一些好用的机制,像 Kafka 用到的零拷贝和 PageCache 等等。我们在设计中需要善用这些机制,可以非常大的优化程序的性能,并且简化我们需要做的时候交给操作系统去完成,并且完成的比我们做的更好更稳定。
# 4. 参考文章
- 本文主要是学习《极客时间-redis 核心技术与实战》专栏总结而来