
 理解calico容器网络通信方案原理
理解calico容器网络通信方案原理
# 0. 前言
Calico是k8s中常用的容器解决方案的插件,本文主要介绍BGP模式和IPIP模式是如何解决的,并详细了解其原理,并通过实验加深理解。
# 1. 介绍Calico
Calico是属于纯3层的网络模型,每个容器都通过IP直接通信,中间通过路由转发找到对方。容器所在的节点类似于传统的路由器,提供了路由查找的功能。每个容器所在的主机节点扮演了虚拟路由器 (vRouter)的功能,vRouter必须有某种方法,能够知道整个集群的路由信息。
之前提到的FlannelHost Gateway模式 (opens new window)方案是不能跨二层网络,是因为它只能修改主机路由,Calico把改路由表的做法换成了标准的BGP路由协议。相当于在每个节点上模拟出一个额外的路由器,由于采用的是标准协议,Calico模拟路由器的路由表信息可以被传播到网络的其他路由设备中,这样就实现了在三层网络上的高速跨节点网络。
BGP(Border Gateway Protocol)是一种用于在互联网中交换路由信息的协议。它是一种自治系统(AS)之间的路由协议,用于在不同的自治系统之间交换路由信息。BGP协议的主要作用是将路由信息从一个自治系统传递到另一个自治系统,以便实现互联网的全球路由。
但现实中的网络并不一定支持BGP路由,在这种情况下可以使用IPIP隧道 (opens new window)模式来传输数据。
# 2. Calio架构
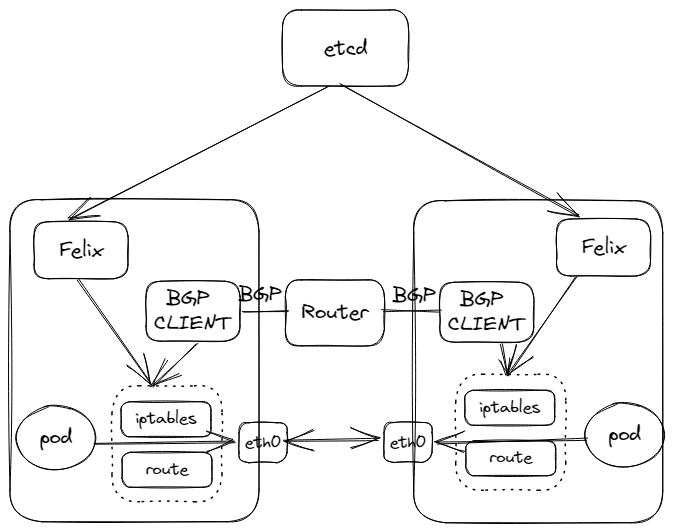
Felix
Felix是一个守护程序,作为agent运行在托管容器或虚拟机的Calico节点上。Felix负责刷新主机路由和ACL规则等,以便为该主机上的Endpoint正常运行提供所需的网络连接和管理。进出容器、虚拟机和物理主机的所有流量都会遍历Calico,利用Linux内核原生的路由和iptables生成的规则。
BGP Client
Calico在每个运行Felix服务的节点上都部署一个BGP Client(BGP客户端)。BGP客户端的作用是读取Felix编写到内核中的路由信息,由BGP客户端对这些路由信息进行分发。当Felix将路由插入Linux内核时,BGP客户端将接收它们,并将它们分发到集群中的其他工作节点。
Node-to-Node Mesh
该模式为默认模式,在BGP下,集群中的每一个节点的BGP Client都需要和其他所有节点的BGP Client进行通信来交换路由。
但随着节点数量增加,连接数会以N^2规模增加,给集群网络带来巨大的压力。
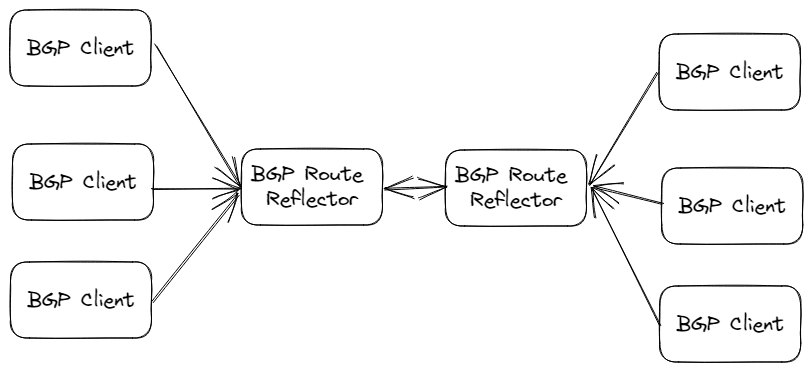
BGP Route Reflector
Calico会指定几个节点负责专门跟其他所有节点进行连接并交换路由信息,从而学习到全局的路由信息。而其他节点也只需要跟这几个节点进行通信来获取到整个集群的规则信息。
# 3. BGP模式
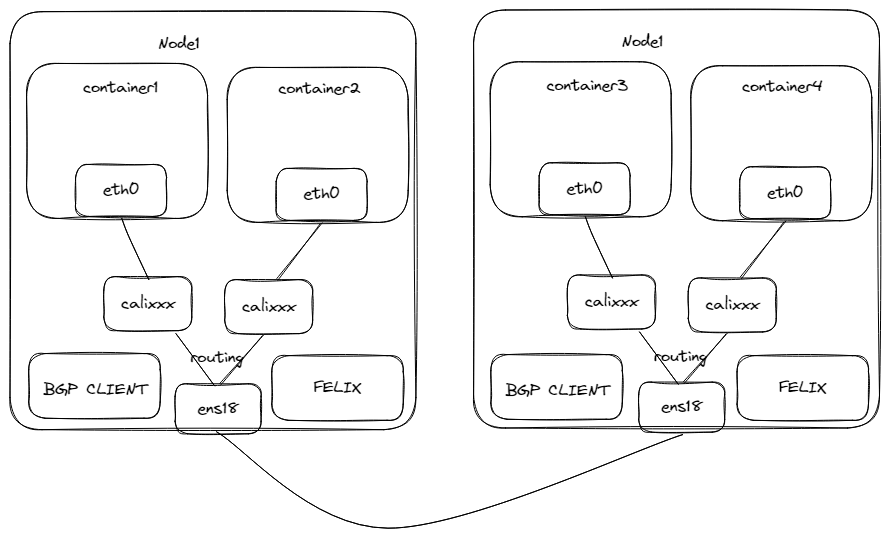
每个容器都会创建一对veth pair网卡,一端放在容器内部,另一端放在宿主机中,容器中发送的IP包通过veth pair网卡可以达到宿主机的网络协议栈中。
Felix会通过监听etcd来获取其他节点的相关信息,然后添加本地路由:
- 通往其他节点容器的IP包下一条到其节点物理网卡中。
- 通过本机节点容器的IP包到calixxx网卡中,然后进入到容器中。
BGP Client会读取Felix写入到本地的路由,再通过进行分发到网络中。
# 4. 手动模拟BGP模式实验
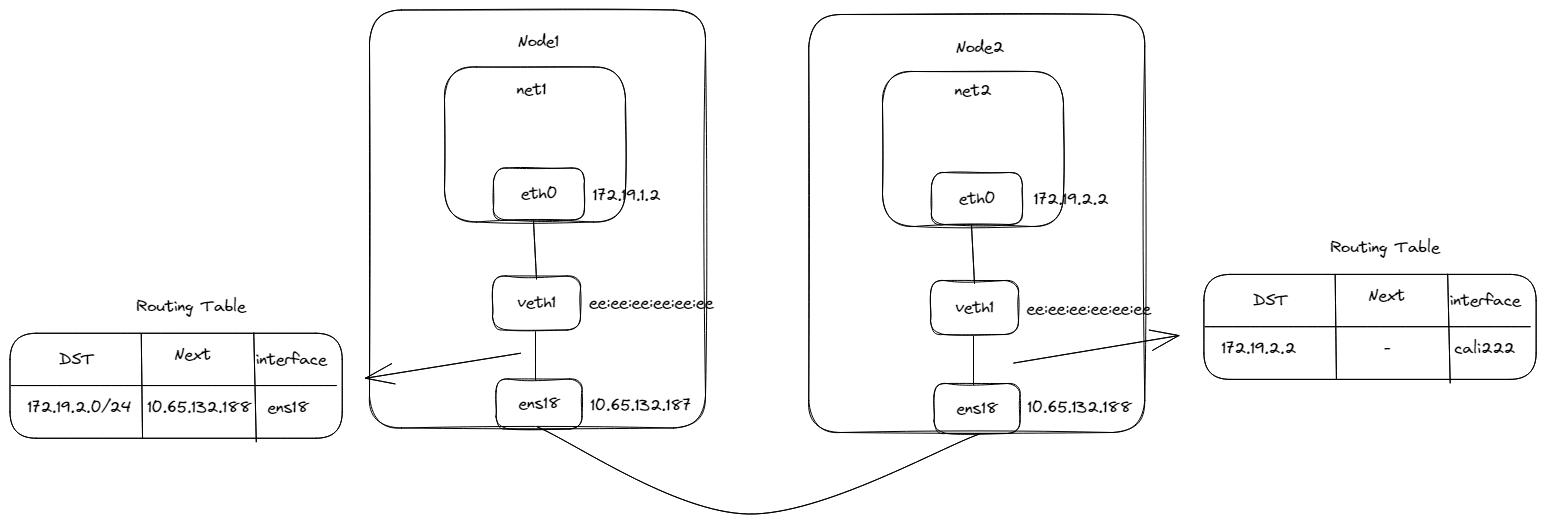
# 4.1 操作
首先在Node1中创建Network Namespace命名为net1
ip netns add net1
然后创建一对veth pair设备veth0和veth1,将veth0放到net1中,拉起并设置好ip地址172.19.1.2/24,veth1也拉取但不用设置IP地址,但需要设置默认的MAC地址为ee:ee:ee:ee:ee:ee
ip link add veth0 type veth peer name veth1
ip link set dev veth0 netns net1
ip netns exec net1 ip link set veth0 up
ip netns exec net1 ip addr add 172.19.1.2/24 dev veth0
ip link set dev veth1 up
ip link set dev veth1 address ee:ee:ee:ee:ee:ee
2
3
4
5
6
7
net1配置的路由有点意思,和一般配置的路由不同,所有的报文都需要通过veth0设备发送到下一跳的地址为169.254.1.1,而这个地址在整个平台找是不存在的,这是一个默认的网关,那如何达到该地址呢?
ip netns exec net1 ip r a 169.254.1.1 dev veth0
ip netns exec net1 ip r a default via 169.254.1.1 dev veth0
2
通过设置veth1设备proxy_arp,可以对于任何ARP请求到达veth1时,都响应自己的Mac地址,也就是ee:ee:ee:ee:ee:ee
当访问网关的时候,首先是需要进行ARP请求,请求通过veth0设备达到了veth1中,因为设置proxy_arp,会将自身的mac地址ee:ee:ee:ee:ee:ee作为arp回复。
而容器的后续报文目的IP地址是目的容器的IP地址,而mac地址变成了网关MAC地址ee:ee:ee:ee:ee:ee,而网关的IP地址并不会出现在任何的数据包中,也没人关心这个具体的地址是什么,只要能找到arp就行。
echo 1 > /proc/sys/net/ipv4/conf/veth1/proxy_arp
数据包已经从net1中通过veth1作为网关达到宿主机的网络协议栈中,再通过设置宿主机路由表,将目的地址为Node2容器网段的数据包通过Node2 ens18网卡地址作为下一跳地址。
ip r add 172.19.2.0/24 via 10.65.132.188 dev ens18
目的地址为Node1的net1时,需要配置通过路由表到达veth1网卡,然后再进入到net1中。
ip r add 172.19.1.2 dev veth1
再在Node2中重复Node1的操作创建Network Namespace net2,并初始化网络配置。
ip netns add net2
ip link add veth0 type veth peer name veth1
ip link set dev veth0 netns net2
ip netns exec net2 ip addr add 172.19.2.2/24 dev veth0
ip netns exec net2 ip link set veth0 up
ip link set dev veth1 up
ip link set dev veth1 address ee:ee:ee:ee:ee:ee
ip netns exec net2 ip r a 169.254.1.1 dev veth0
ip netns exec net2 ip r a default via 169.254.1.1 dev veth0
ip r add 172.19.1.0/24 via 10.65.132.187 dev ens18
ip r add 172.19.2.2/32 dev veth1
2
3
4
5
6
7
8
9
10
11
12
13
# 4.2 分析
在Node1 net1中ping Node2 net2,然后使用tcpdump监听Node1的veth1,结果如下:
# tcpdump -i veth1 -ne
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth1, link-type EN10MB (Ethernet), capture size 262144 bytes
10:38:29.713322 02:1c:9c:83:87:f2 > Broadcast, ethertype ARP (0x0806), length 42: Request who-has 169.254.1.1 tell 172.19.1.2, length 28
10:38:30.205862 ee:ee:ee:ee:ee:ee > 02:1c:9c:83:87:f2, ethertype ARP (0x0806), length 42: Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee, length 28
10:38:30.205922 02:1c:9c:83:87:f2 > ee:ee:ee:ee:ee:ee, ethertype IPv4 (0x0800), length 98: 172.19.1.2 > 172.19.2.2: ICMP echo request, id 37475, seq 1, length 64
10:38:30.206393 ee:ee:ee:ee:ee:ee > 02:1c:9c:83:87:f2, ethertype IPv4 (0x0800), length 98: 172.19.2.2 > 172.19.1.2: ICMP echo reply, id 37475, seq 1, length 64
2
3
4
5
6
7
8
可以看到,先是发送arp请求获取172.19.1.2的mac地址,因为设置了proxy_arp,所以会将自身的Mac地址进行回复,在后面的ICMP包中,目的IP地址为目的容器IP地址172.19.2.2,而目的Mac地址为veth1的Mac地址ee:ee:ee:ee:ee:ee
再使用tcpdump监听Node2的ens18网卡,结果如下:
# tcpdump -i ens18 host 172.19.2.2 -en
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens18, link-type EN10MB (Ethernet), capture size 262144 bytes
10:52:43.993140 fa:16:3e:d3:f6:3a > fa:16:3e:b1:9a:65, ethertype IPv4 (0x0800), length 98: 172.19.1.2 > 172.19.2.2: ICMP echo request, id 4349, seq 1, length 64
10:52:43.993291 fa:16:3e:b1:9a:65 > fa:16:3e:d3:f6:3a, ethertype IPv4 (0x0800), length 98: 172.19.2.2 > 172.19.1.2: ICMP echo reply, id 4349, seq 1, length 64
2
3
4
5
6
数据包从Node1中到达了Node2 ens18网卡,源IP和目的IP分别为net1和net2的IP地址,而mac地址是Node1和Node2的物理网卡ens18 Mac地址.
使用tcpdump监听veth1网卡,结果如下:
# tcpdump -i veth1 -en
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on veth1, link-type EN10MB (Ethernet), capture size 262144 bytes
10:58:13.780247 ee:ee:ee:ee:ee:ee > fa:63:d4:dc:25:01, ethertype IPv4 (0x0800), length 98: 172.19.1.2 > 172.19.2.2: ICMP echo request, id 41971, seq 1, length 64
10:58:13.780288 fa:63:d4:dc:25:01 > ee:ee:ee:ee:ee:ee, ethertype IPv4 (0x0800), length 98: 172.19.2.2 > 172.19.1.2: ICMP echo reply, id 41971, seq 1, length 64
2
3
4
5
6
查看Node2的路由
# ip r
...
172.19.2.2 dev veth1 scope link
...
2
3
4
数据包达到Node2 ens18网卡后,解开mac头,到达网络协议栈中,通过路由,将目的地址为172.19.2.2的数据包都进入到veth1网卡中,最终进入到net2中
# 5. IPIP隧道模式
该模式的解决方式是在物理机A和物理机B之间打一个隧道,这个隧道有两个端点,在端点上进行封装,将容器的IP作为乘客协议放在隧道里面,而物理主机的IP放在外面作为承载协议。这样不管外层的IP通过传统的物理网络,走多少跳到达目标物理机,从隧道两端看起来,物理机A的下一跳就是物理机B。